新しいアンケートを創る
[紹介論文] T. Kawamoto and T. Aoki (2019) Democratic classification of free-format survey responses using a network-based framework. Nature Machine Intelligence, 1, 322–327.
先日Nature Machine Intelligenceから出版された我々の論文の簡潔なまとめです(簡潔じゃないバージョンはこちら)。
この記事の見出し
背景
この世の荒ぶる意見を集約したい
ネット上には、膨大な意見や感情が日々垂れ流されています。しかしいくら何十万人もの人が持論を主張し、共感を呼びかけても、それらは通常、一瞬誰かの目に止まって、あとは電子的なゴミとなるだけです。このような「垂れ流して終わり」の形式ではなく、何かしら体系だった情報を構築する形式を実現したいと思いました。
意見や感情の集約は、人が関わる問題のため、非常に自由度が高く、漠然とした問題です。このような問題は、人文・社会科学の分野で研究されています。しかし、ここには「大量の意見をどう処理するか」という技術的な問題も存在しています。

人力による意見集約は、膨大な労力がかかるうえに、集計者の主観による恣意性も入る(写真提供:香川大学 時岡晴美氏)
新しいアンケートを創る
アンケートというのはおそらく太古の昔から存在しています。インターネットの時代になってウェブアンケートもできるようになりましたが、基本的な仕組みは昔から変わっていません。この、昔からあるアンケートというありふれたものを新しくすることで、意見集約という漠然とした問題を、数理的に扱えるデータ解析の問題に変換できると思いました。
注意点とポイント:
- アンケートデータを後処理としてデータ解析するのではなく、データを収集する段階、すなわちアンケートシステムそのものを工夫することがポイントです。
- 実際に意見集約を研究されている方は、ここでの提案手法は、解析を効率化・解析の根拠を後ろ盾するため前処理だと思ってください。(この話は、“この方法があれば意見集約の研究は要らなくなる”というような内容ではありません。)
研究内容
一言で言うと、「大規模な自由記述式アンケートを、グラフ(ネットワーク)データとして収集すると、効率よくフェアな集計ができるよ」という話です。
自由記述式アンケートシステム
この論文では、以下のようなアンケートの仕組みを提案しています。
与えられた質問に対し、回答者に次の2つを答えてもらいます。
- ランダムに数個抽出された他人の回答を読み、賛成するかどうかを回答する(選択式回答)
- 抽出された回答のなかに完全に自身の回答と一致するものがなければ、自分の回答を書き込む(自由記述式回答)
上の手順は逆でも構いません。実際、論文では(説明のしやすさの都合上)自由記述回答を最初にし、その後他人の回答と比較するという手順を提案しています。
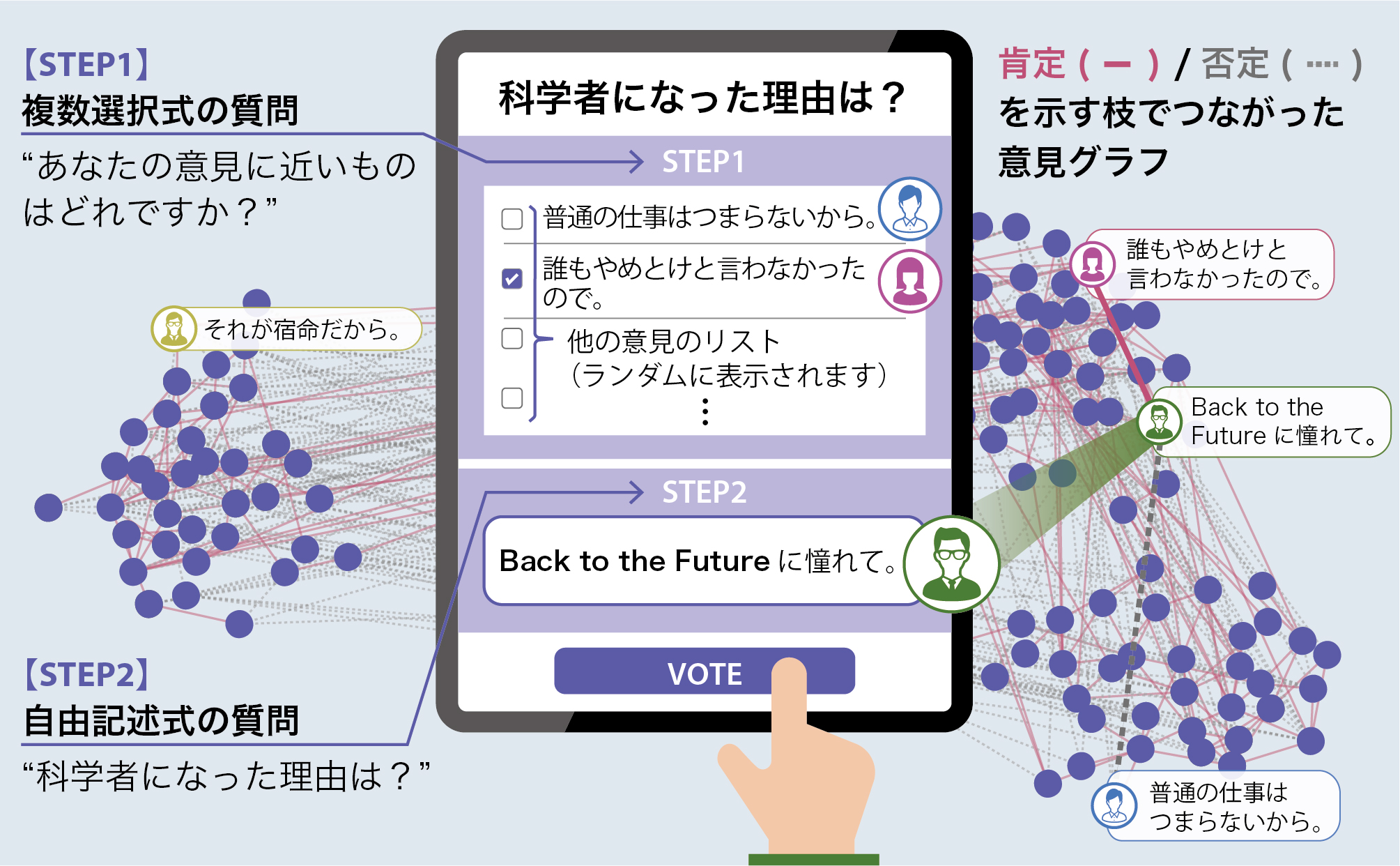
投票クラスタリング概念図
こうして集まったデータは、上図のようなグラフ(ネットワーク)を構成します。グラフの一つ一つの頂点が回答者の意見文章を表し、枝が意見間の関係性を表します。このデータにグラフ分割アルゴリズム(機械学習の一種)を施すことによって、自由記述を含む回答群を、意味として似たものにグループ分けすることができます(下図)。

アンケート実施者の前処理・後処理は、以下の2つです。
- [前処理] 質問文章と、各質問についての幾つかの回答候補をセットする(どんなアンケートにも必要)
- [後処理] グループ分けした後の意見集合を見て、グループの意味を解釈する
基本的には、これだけの非常にシンプルな話です。
実例
論文では、2つの実証例を載せています。
そのうちの一つが、2016年アメリカ大統領選挙です。
“#NeverHillary or #NeverTrump?”というタイトルで、ウェブ上および、大統領ディベートの会場(ネバダ大学 ラスベガス校)での街頭アンケートによってデータを収集しました。

2016年アメリカ大統領選のPresidential Debateの際、ネバダ大学ラスベガス校に設置されたCNN特設スタジオ
得られたデータから、以下のような3つの意見グループが抽出されました。
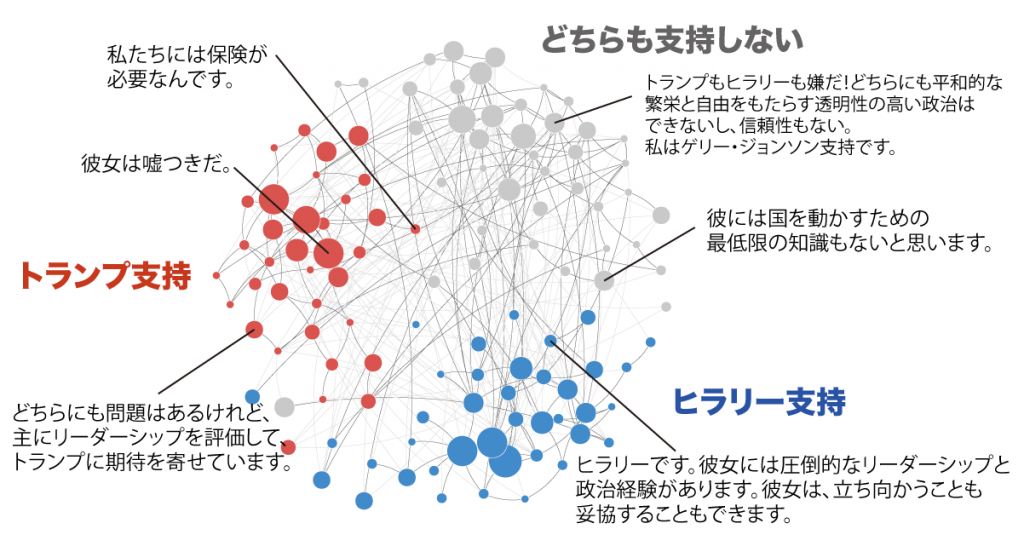
ヒラリー支持者とトランプ支持者のグループが出現することは、自明でしょう。しかし、回答文章自体には、誰を支持しているのか明記されていないものも多くあります。この曖昧性は、ヒラリー支持でもトランプ支持でもないグループにおいては、一層非自明です。
このデータは、Githubのリポジトリから取得することができます。
この方法の特徴
大事なポイントを最小限にまとめると次の3つです。
- [自由記述回答を統計解析できる] 自然言語(回答文章)は回答者同士が互いに参照し合うためだけに使い、アルゴリズムは言語データを一切使うことなく文章の分類を行います。意見の類似性など、尺度が曖昧な部分はすべて人間側で処理するので、グラフデータ処理の時点では言語に由来する曖昧性がありません。
これによって、ちゃんと統計解析ができるようになります。 - [フェアな分類] ここでの回答結果の分類は、回答者自身の選択のコンセンサスによって決まっています。
これは、集計者が独断的な判断と基準による全手動の分類とも、単語の類似性等から決める全自動の分類とも異なる、”民主的”な分類になっています。 - [スケーラビリティ] このフレームワークでは、各回答者が集計作業を分散処理していることになります。こうして集まったデータを、グラフ分割アルゴリズムでまとめ上げることにより、数万人の自由記述アンケートでも効率良く集計することができます。
その他
先行研究
この研究には、特に他の論文から着想を得たという背景はありません。
しかしもちろん、アンケートを学問するというのは当然昔からたくさんやられています。数理的な扱いとは別に、社会学の分野で昔からどのようにアンケートを実施すべきか、どのような利点・欠点があるかの議論が脈々となされてきました。数理的な側面からも、特に政治学の方面で多くの論文が出版されています。意見集約という視点からは、自然言語処理で回答文章を処理したり、クラウドソーシングで処理する論文も出ています。この研究を思いついたとき、グラフ分割でアンケート集計する論文もきっと既にあるだろうと思ったのですが、現時点でまったく同じ研究は、確認できていません。
裏話
この論文はアイディア論文で、基本的な提案内容は非常に単純です。チャラチャラした論文に見えますが、実はかなり気合入っています。
- 研究を思いついたのは2014年春。出版されたのは2019年夏。
- データ収集するためにウェブシステムを開発(論文データ収集時点でver.02、2019年現在でver.05)。
- 論文では触れていない変種のシステムもいくつか実装してみて、実際実験している。
- アメリカ大統領選挙(2016年)のデータのためにラスベガスへ行き、大統領ディベート会場で歩いている人(200人くらい)に片っ端から声をかけてデータを集めた。
- 卒業生アンケートデータを集めるために香川大学の卒業生3000人に郵送でアンケート募集。手法の妥当性を検証するために、集まった数千件もの回答を人力で分類してもらった。
- Glenn Paquette氏に英文校正をお願いした。
実証実験
今回の論文での手法を実装したシステムを、「投票クラスタリング」(英語名 voteclustering)と呼んでいます。この手法の研究・開発は、まだまだ始まったばかりです。アンケートシステムを実際に稼働させながら実証実験を重ね、今後のシステム開発・手法研究を進めていく予定です。
投票クラスタリングの紹介ウェブサイト
https://ja.voteclustering.orgにおいて、実際にアンケートのリクエストを受け付けていますので、このアンケートを使ってみたい方は、ご連絡ください。
(*2019年8月の段階では、紹介サイトの動画の実装と最新バージョンの実装は同じではありません。)
今後の情報発信
こちらで情報発信していきます。フォローお願いします!
- Twitterアカウント:@voteclustringJP
- Facebookページ:@voteclusteringJP











