マルチモーダル絵文字予測🤔🤔🤔
[紹介論文] Barbieri, F., Ballesteros, M., Ronzano, F., & Saggion, H. (2018). Multimodal Emoji Prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 679–686.
概要
画像とテキストから絵文字を1つ予測する。
データセット:Instagram(高頻度20絵文字のうち1つだけを使っているテキストのみ;299,809件)。
入力:画像はResNet,テキストはFastTextによって表現を獲得し,つなぎ合わせたもの(concatenate)。
分類器:ロジスティック回帰(L2正則化)
出力:絵文字
背景
筆者はTwitterのテキストから絵文字を予測している(Barbieri, et al., 2017 @ EACL)。画像も追加したら精度が上がるかもしれない。TwitterではできないのでInstagramを使おう。
結果と考察
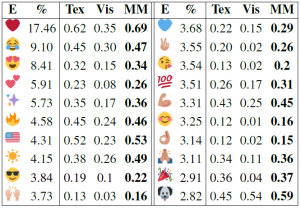
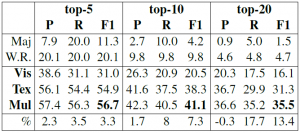
Texはテキストのみ,Visは画像のみ,NMは提案手法である。高頻度絵文字20種を対象としているが,これをtop-5, top-10のみで行った場合も示している。
- テキストのみで予測しやすい絵文字は❤と🇺🇸である。後者はテキスト中にUSAなどと書かれているからであろう。
- テキストのみで予測しにくい絵文字は👌と🙌である。
- 画像のみで予測しやすい絵文字は🐶☀💪である。犬の写真,明るい写真,ジムの写真などが該当する。
- マルチモーダルによる予測では,全ての絵文字についてテキストのみ・画像のみより精度が向上している。それぞれが相補的に働いていると思われる。
- 5種類よりも10種類,10種類よりも20種類の分類の方が提案手法による改善の度合いが大きい。
ライセンス等
本論文はCC-BY 4.0にてライセンスされている。本文中の画像(表)は論文より転載(©2018 Association for Computational Linguistics.)。











